Non-functional requirements are for those that install and maintain operational code, i.e. the help desk and operators
Every developer needs to be aware of what those non-functional requirements are and why operations personnel and help desk personnel are indirect customers that are really important. There is no way for these guys to be unhappy and it not to back up into development as an urgent problem!
Functional Requirements
Functional requirements are baked into the code that developer's deliver (interpreted or compiled). Events from input devices (network, keyboard, devices) trigger functions to convert input into output -- all functions have the form: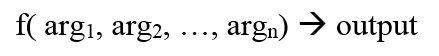
This is true whether you use an object-oriented language or not.
Non-functional requirements involve everything that surrounds a functional code unit. Non-functional requirements concern things that involve time, memory, access, and location:
| Performance |
|
| Availability |
|
| Capacity |
|
| Continuity |
|
| Security |
|
I won't spend any time on performance because this is the non-functional requirement that everyone understands.
Non-functional requirements are slightly different between desktop applications and services; this article is focused on non-functional requirements for services.
If you have any knowledge of ITIL you will recognize that the highlighted items deal with the warranty of a service. In fact, the functional requirements involve the utility of a service, the non-functional requirements involve the warranty of a service.
Availability

Developer's need to be aware of single-points of failure (i.e. services hard-coded to a specific IP) which causes fits in operations that are not running virtual machines (VM) that can have virtual IPs . The requirement to create code that is not reliant on static IPs or specific machines is a non-functional requirement. Availability is simplified in operations if the code is resilient enough to allow itself to easily move (or be replicated) among servers.
Availability non-functional requirements include:
- Code to verify that customers are in their user windows
- Automatic installation of CI or mechanisms
- Ability to detect and prevent manual errors for a CI
- Ability to easily move code between servers
Capacity

This may look like an availability issue, but it is caused because you can't handle the capacity requested.
Internet services can't provide enough capacity with a single machine and operations personnel need to be able to run multiple servers with the same software to meet capacity requirements. The ability to run multiple servers without conflicts is a non-functional requirement. The ability to take a failing node and restart it on another machine or VM is a non-functional requirement.
Capacity non-functional requirements include:
- Ability to run multiple instances of code easily
- Ability to easily move a running code instance to another server
Continuity

Where availability and capacity often involve redundancy inside a single operation center, continuity involves geographic and network redundancy. Continuity at best involves having multiple servers that can work in geographically distributed operation centers. At worst, you need to be able to have a master-slave fail over model with the ability to journal transactions and eventually bring the master back up.
Continuity non-functional requirements include:
- Resilience of a code base to potential network outages, i.e. ability to retry transactions or find a new server
- Making sure that correct error messages are returned when physical failures are encountered, i.e. if the network is unavailable then don't give the end-user a message "Customer record has errors, please correct".
- Ability to recognize inconsistent data and not continue to corrupt data inside the database.
Security

Where access is concerned, how difficult will it be for operations personnel or help desks to set up security for users?
Developer's build in different levels of access into their applications without considering how difficult it will be for a 3rd party (help desk or operations) to set-up end users.
Data integrity is another non-functional requirement. Developer's need to consider how their applications will behave if the program encounters corrupted data due to machine or network failures. This is not as important an issue in environments using RAID or redundant databases.
Security non-functional requirements include:
- Ease of a help desk to set up a new user on an application
- Ability to configure a user's rights to enable them only to access the functions that they have a right to
- Ensuring through data redundancy or consistency algorithms that data is not corrupted
When You Forget Non-Functional Requirements...

For example, it is easy to be fooled into building software that is tied to a single machine, however, this will not scale in operations and cause problems later on. One of the start-ups I was with built a server for processing credit/debit card transactions without considering non-functional requirements (capacity, continuity).
It cost more to add the non-functional requirements than it cost to develop the software!
Every non-functional requirement that is not thought through at the inception of a project will often represent significant work to add later on. Every such project is a 0 function point project that will require non zero cost!
Generally availability, capacity, and continuity is not a problem for services developed with cloud computing in mind. However, there are thousands of legacy services that were developed before cloud computing was even possible.
If you are developing a new service then make sure it is cloud enabled!
Operations People are People Too

Hardware and OS solutions exist for making up for poorly written software that assumes single machines or does not take into account the environment that the code is running in, but that can come at a fairly steep cost in infrastructure.
The world has moved to services and it is no longer possible for developers to ignore the non-functional requirements involved with the code that they are developing. Developer's that think through the non-functional requirements can reduce costs dramatically on the bottom line and quality of service being delivered.
The guys that run operational centers and help desks are customers that are only slightly less important than the end-user. Early consideration of the non-functional requirements makes their lives easier and makes it much easier to sell your software/services. It is no longer possible for competent developers to be unaware of non-functional requirements.
Other Articles
 |
No Experience Necessary | Counter-intuitive evidence why years of experience does not make developers more productive |
 |
Shift Happens | Why scope shift on development projects is inevitable and why not capturing requirements at the start of a project can doom it to failure. |
 |
Inspections are not Optional | Software inspections are intensive but evidence shows that for each hour of inspection you can reduce QA by 4 hours! |